随着深度学习技术的突破,该方法极大地促进了 SR领域研究,很多工作在基准数据集上取得了显著成果[1]。即:假设 LR 图像是由HR图像通过使用理想内核(例如,双三次)进行下采样得到的。借助于AI技术的不断革新,腾讯优图内容生成团队深入研究超分技术,提出了图像盲超分新算法,更好地处理真实世界图像超分,相关论文发表在神经信息处理系统大会NeurIPS 2021。
而最近的研究[2] 表明,预训练的 SR 模型对 LR 图像的退化很敏感。高斯内核的不匹配可能会导致 SR 结果过度锐化或过度平滑,而对于运动模糊内核,可能会造成重建结果中出现抖动和伪影。 由于盲超分与真实场景的密切关系,这个问题越来越受到人们的关注,然而现有的盲超分方法不足以处理真实场景中存在的各种退化类型的图片。
究其原因,就是现有方法缺乏紧密联系退化图像和模糊核的有效约束:以ESRGAN为代表的超分方法基于标准的数据集训练,没有考虑真实数据中存在的模糊退化问题,在处理包含未知退化的数据时仍然会产生模糊的结果。尽管有些研究者已经提出了一些代表性的工作[3,4,5,6],文献[3]基于跨尺度图像patch的最大相似性使用生成对抗网络 (GAN) 估计内核,但是其依赖对内核的手工约束先验,无法直接捕获与内核相关的特征。文献[4]提出了一个迭代内核校正 (IKC) 框架,以迭代的方式逐渐缩小内核和 SR 结果之间的不匹配,从而校正内核估计。 文献[5]提出在生成的下采样图像和真实输入之间引入频率一致性约束来估计空间域中的模糊核。然而,其训练需要一定量的具有相同退化的数据,并且无法捕获各个方向的模糊多样性,限制了它处理任意内核退化的 LR 图像的通用性。腾讯优图内容生成团队发现,已有的方法缺少紧密联系退化图像和模糊核的有效约束,从而限制了模糊核估计的准确性。

图1 在真实老照片实例中,腾讯优图所采用的方法的视觉效果优于已有方法
01 退化图像的频谱图和模糊核存在结构相似性
为解决以上问题,腾讯优图从一个全新的角度捕捉 LR 图像中局部分布的卷积退化特征。腾讯优图发现傅立叶频谱中包含了模糊核的形状结构特征,相对于图像空间特征,频域上获得的内核表示更稳健、更有利于模糊核估计。 在不同形式的模糊核满足稀疏性的合理假设下,频域中的核估计比空间域中的核估计更有效。基于卷积定理和稀疏性分析,证明了退化 LR 图像的傅立叶频谱隐含了频域中退化核的形状结构,可以用来更准确地预测未知核。
基于此,腾讯优图设计了一个 Spectrum-to-Kernel (S2K) 转换网络,直接从退化的 LR 的频谱中获得内核插值结果,这是第一个在频域而不是空间域中估计内核的工作。实验结果表明,这个方法准确估计了目标内核,并且对不同类型的内核具有很高的通用性。此外,当与现有的非盲方法相结合时,在合成和真实图像的质量评估和视觉感知方面取得了优于现有盲超分方法的最佳结果。
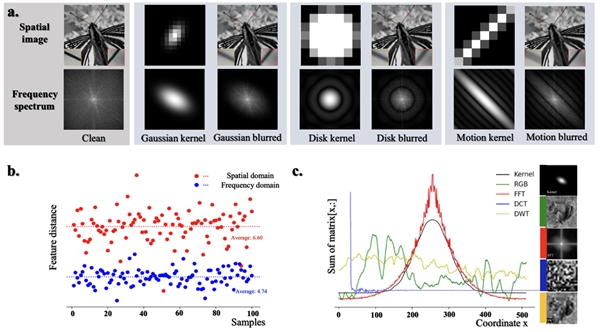
图2 退化图像与模糊核之间的关系表明:频域相比于空域关联更紧密
总体而言,这一方法为图像对应恢复高分辨率做出了以下贡献:
• 从理论上证明:对于常见的稀疏核,从频域上重建,比在常用的空间域上更有效。
• 腾讯优图分析了内核估计优化目标对盲超分性能的影响,并设计了一个新的网络 S2K 用于从傅立叶幅度谱估计内核。
• 当结合现有的非盲SR模型时,腾讯优图提出的方法在合成和真实世界图像上都实现了比现有的盲超分方法更好的效果。
02 S2K网络:从频域预测模糊核
与以往的空域核估计方法不同,S2K 是第一个尝试完全基于深度学习在频域进行核估计的方法。腾讯优图从频率空间中的目标内核。 Generator 是一种编码器-解码器结构(图4),以 LR 图像的 256×256 单通道幅度谱作为输入。 在通过步长为 2 的输入层后,特征被送到 U-net网络,其中七个下采样 Conv 层和上采样转置 Conv 层中的每个层之间都有shortcut连接,它们具有相同的特征大小。 最后,我们通过输出层获得单通道估计核图。
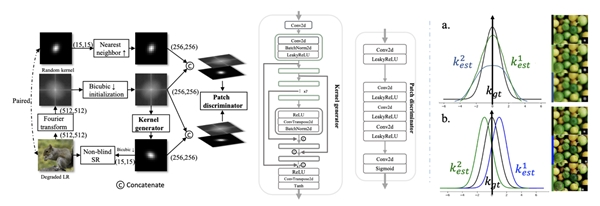
图3 S2K方法框架
图4 更是直观地展示了频谱图的形状结构有利于频域中内核的重构。在数学上,傅里叶域和空间域之间高斯核的方差成反比。右图展示了不同尺度的 S2K预训练模型的中间特征图的可视化结果。频域中退化 LR 图像的形状在S2K网络中一步步被转换成内核形状。

图4 腾讯优图的S2K网络有效利用了频域的结构信息
03 实验结果
合成数据实验:通过将提出的 S2K 与非盲方法相结合,并在表中提供了与现有方法的比较。与现有的单图像核估计方法[7,8]相比,腾讯优图提出的方法获得了更高的PSNR和SSIM性能。
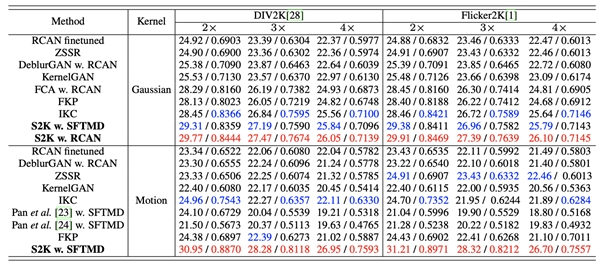
图5 合成数据上定量指标对比
而在视觉效果上,我们的结果也更加清晰。

图6 合成数据上视觉效果对比
核估计误差定性和定量比较:我们提供了不同方法估计模糊核的误差比较,包括可视化的图和定量的L1误差,结果表明,腾讯优图的S2K可以更准确地估计高斯核、运动模糊核、Disk核。
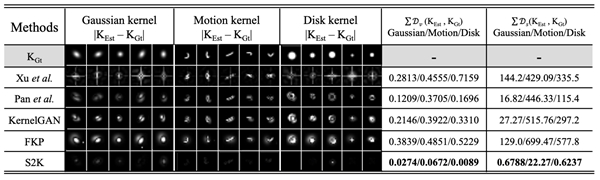
图7 核估计误差比较
真实数据实验:对于真实图像,我们使用数据集 [9] 中近距离拍摄的配对图像作为内容保真度参考。 比较方法包括 KernelGAN、LP-KPN、IKC 和 NTIRE20 冠军方法。我们采用方差较小的高斯核估计设置,并用上文中提出的 S2K 替换方法[2]的核估计部分。 4×SR的结果如图8所示。与NTIRE20冠军方法[10]相比,此结果实现了更高的保真度(红色)和更少的伪影(绿色)。 严格意义上来说,真实图像没有ground truth,因此我们提供了真实图像SR结果的无参考评估指标比较,如图8右所示。

图8 真实图像超分结果对比
本文从理论上论证了频域中的特征表示比空间域中的特征表示更有利于核估计。 我们进一步提出了 S2K 网络,它充分利用了退化 LR 图像频谱的形状结构,并通过有效的隐式跨域转换,直接输出估计的内核。 对合成和真实世界数据集的综合实验表明,当将 S2K 与现成的非盲SR模型结合时,腾讯优图在视觉和定量上都比最先进的盲SR方法获得了更好的结果。
腾讯优图实验室深入研究以图像、视频超分为代表的高精度画质优化技术,并在CVPR、NeurIPS、AAAI等国际顶级学术会议上发表多篇论文,在画质增强国际权威竞赛NTIRE中也获得多项竞赛冠军。此外,腾讯优图联合上海大学电影学院、上海电影厂在画质增强技术方向获得由中国电影电视技术学会电影高新技术专业委员会颁发的《电影科技创新成果奖》,专业技术得到了电影电视行业专家们的广泛认可。

论文题目:
Spectrum-to-Kernel Translation for Accurate Blind Image Super-Resolution
论文下载地址:https://openreview.net/pdf?id=94Sj1CcC_Jl
参考文献:
[1]Ying Tai, Jian Yang, Xiaoming Liu, and Chunyan Xu. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 4539–4547, 2017.
[2]Xiaozhong Ji, Yun Cao, Ying Tai, Chengjie Wang, Jilin Li, and Feiyue Huang. Real-world super-resolution via kernel estimation and noise injection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2020.
[3]Sefi Bell-Kligler, Assaf Shocher, and Michal Irani. Blind super-resolution kernel estimation using an internal-gan. In Advances in Neural Information Processing Systems (NeurIPS), pages 284–293, 2019.
[4]Jinjin Gu, Hannan Lu, Wangmeng Zuo, and Chao Dong. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1604–1613, 2019.
[5]Xiaozhong Ji, Guangpin Tao, Yun Cao, Ying Tai, Tong Lu, Chengjie Wang, Jilin Li, and Feiyue Huang. Frequency consistent adaptation for real world super resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 1664–1672, 2021.
[6]Jingyun Liang, Kai Zhang, Shuhang Gu, Luc Van Gool, and Radu Timofte. Flow-based kernel prior with application to blind super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10601–10610, 2021.
[7]Jinshan Pan, Deqing Sun, Hanspeter Pfister, and Ming-Hsuan Yang. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1628–1636, 2016.
[8]Liyuan Pan, Richard Hartley, Miaomiao Liu, and Yuchao Dai. Phase-only image based kernel estimation for single image blind deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6034–6043, 2019
[9]Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3086–3095, 2019.